今日复习数据结构的单链表和双向循环链表的知识。
单链表
一、链表的基本信息
1、链表是以结点的方式存储的;
2、每个结点都包含一个data域(数据域)与一个next域(data域存储数据 next域指向下一个结点的位置);
3、链表中每个结点的存储不一定是连续存储的;
4、链表分为带头结点的与不带头结点的。
单链表的逻辑结构图

二、头节点的作用
1、不存放具体的数据;
2、作用就是表示单链表头,此外next域指向第一个结点。
三、单链表的创建
1、步骤:
(1)创建一个单链表的结点对象类,内部至少要有一个数值变量与指向下一个结点的单链表结点对象(其实是结点对象的引用,作用是替代c语言中的指针);
(2)创建一个对单链表进行遍历、添加、修改和删除等操作的工具类,用于对单链表进行操作;
(3)创建一个对单链表进行测试和运行的类。
单链表的结点对象
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
| package 链表.单链表.链表的实现;
public class LinkedNode {
int number;
Object data;
LinkedNode next;
public LinkedNode() {
}
public LinkedNode(int number, Object data) {
this.number = number;
this.data = data;
}
@Override
public String toString() {
return "LinkedNode{" +
"number=" + number +
", data=" + data +
'}';
}
}
|
1
2
3
4
5
6
7
8
9
10
11
12
13
| public class SingleLinkedNode {
LinkedNode headNode = null;
int size;
public SingleLinkedNode(LinkedNode headNode) {
this.headNode = headNode;
this.size = 0;
}
}
|
四、单链表的工具类
1、单链表的非空判断
(1)思路
- 当一个单链表为空时,单链表中只有一个头结点,所以单链表为空否的判断条件为 head.next == null。
(2)代码实现
1
2
3
4
5
6
7
|
public boolean isEmpty() {
return headNode.next == null ? true : false;
}
|
2、单链表的遍历
(1)思路
- 判断链表是否为空(判断头节点的next域是否为空 head.next == null);
- 非空创建一个临时结点对象引用(充当指针);
- 使用while循环,输出结点对象(需要重写结点类中的toString()方法),使用temp = temp.next移动单链表索引,相当于移动c语言中的指针。
(2)代码实现
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
public void traversal() {
if (isEmpty()) System.out.println("该单链表为空!");
LinkedNode tempNode = headNode.next;
for (int i = 0; i < size; i++) {
System.out.println(tempNode);
tempNode = tempNode.next;
}
}
|
3、按照单链表的index查找结点
(1)思路
- 先判断该单链表是否非空,若非空则无需查找直接返回null;
- 检验要查询的index的值是否正确;
- 根据index的值使用for循环找到要相应位置处的结点对象然后返回。
(2)代码实现
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
|
public LinkedNode findByIndex(int index) {
if (isEmpty()) {
System.out.println("单链表为空!");
return null;
} else if (index == size) {
LinkedNode tempNode = headNode.next;
for (int i = 0; i < index - 1; i++) {
tempNode = tempNode.next;
}
return tempNode;
} else if (index < 0 || index > size) {
System.out.println("您输入的index有误!" + index);
return null;
} else if (index == 0){
return headNode;
} else {
LinkedNode temp = headNode.next;
for (int i = 0; i < index - 1; i++) {
temp = temp.next;
}
return temp;
}
}
|
4、单链表的添加(尾部)
(1)思路
- 创建一个结点对象引用,将头结点对象赋值给临时变量对象引用;
- 使用while循环找到单链表的最后一个结点(此处也可以使用findByIndex()方法找到最后结点对象);
- 设置最后一个结点的next指向要加入的结点。
(2)代码实现
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
|
public void add(int number, Object obj) {
LinkedNode addNode = new LinkedNode(number, obj);
if (isEmpty()) {
headNode.next = addNode;
size++;
return;
}
LinkedNode tempNode = headNode.next;
while (tempNode.next != null) {
tempNode = tempNode.next;
}
tempNode.next = addNode;
size++;
}
|
5、向单链表的头部添加结点对象
(1)思路
- 使用头结点即可完成;
- 先将头结点的next的值赋值给新加入结点的next值(addNode.next = head.next);
- 再将新加入的结点赋值给头结点的next。
(2)代码实现
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
public void addFirst(int number, Object obj) {
LinkedNode addNode = new LinkedNode(number, obj);
addNode.next = headNode.next;
headNode.next = addNode;
size++;
}
|
6、向单链表的指定位置插入结点
(1)思路
- 先对 index 要插入的位置进行检测;
- 创建一个临时变量引用指向头结点,使用for循环循环遍历移动索引指向index位置的前一个结点对象;
- 之后的步骤和向链表头部添加结点对象一样,将新结点赋值给 index 的前一个结点的next,再将前一个结点的next指向新加入的结点即可。
(2)代码实现
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
|
public boolean addByIndex(int index, int number, Object obj) {
LinkedNode addNode = new LinkedNode(number, obj);
if (index > size) {
System.out.println("插入的位置有误!无法插入!");
return false;
}
LinkedNode tempNode = headNode.next;
for (int i = 0; i < index - 1; i++) {
tempNode = tempNode.next;
}
addNode.next = tempNode.next;
tempNode.next = addNode;
size++;
return true;
}
|
7、删除指定位置的结点
(1)思路
- 先判断当前要删除的节点是否存在,即对index进行检测;
- 若存在则找到要删除结点的前一个结点;
- 让前一个结点的next指向要删除结点所指向的next即可。
(2)代码实现
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
|
public LinkedNode removerNodeByIndex(int index) {
if (isEmpty()) {
System.out.println("该单链表为空!无法删除!");
return null;
}
LinkedNode delNode = findByIndex(index);
if (delNode == null) {
System.out.println("您要删除的元素不存在!");
return null;
}
LinkedNode tempNode;
if (index == 1){
tempNode = headNode;
}else {
tempNode = findByIndex(index - 1);
}
tempNode.next = tempNode.next.next;
size--;
return delNode;
}
|
8、修改指定位置的结点
(1)思路
- 同样是先判断要修改的结点是否存在;
- 若存在则找到当前要修改的节点,然后有两种做法,一种是直接根据传进来的参数修改当前结点的数据即可,另外一种则是根据传入的数据新创建一个结点对其进行交换即可,本次采用第二种方式进行修改;
- 第二种的修改方法,要新加入结点,先找到要修改的前一个结点。
- 将要修改结点的next的值赋值给要修改结点的next;
- 将修改结点的前一个结点的next指向新的结点即可。其实这几步的操作可以简单概括为先删除index位置的结点,再在index位置新加入一个结点即可。
(2)代码实现
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
|
public LinkedNode updByIndex(int index, int newNumber, Object obj) {
LinkedNode oldUpdNode = findByIndex(index);
if (oldUpdNode == null) {
System.out.println("您要修改的元素不存在");
return null;
}
LinkedNode updNode = new LinkedNode(newNumber, obj);
LinkedNode tempNode = headNode.next;
for (int i = 0; i < index - 2; i++) {
tempNode = tempNode.next;
}
updNode.next = tempNode.next.next;
tempNode.next = updNode;
return oldUpdNode;
}
|
9、根据结点的编号对其进行排序
(1)思路
- 本次采用冒泡排序的方式对插入的结点进行排序;
- 先检测数组不为空则开始排序;
- 从第一个结点开始比较,当第一个结点的number值比后一个大时交换两个结点的位置。
(2)代码实现
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
|
public boolean sort(){
if (isEmpty()) {
System.out.println("单链表为空!无法排序");
return false;
}
for (int i = 1; i <= size - 1; i++) {
for (int j = 1; j <= size - i; j++) {
LinkedNode temp0 = findByIndex(j - 1);
LinkedNode temp1 = findByIndex(j);
LinkedNode temp2 = findByIndex(j + 1);
if (temp1.number > temp2.number) {
temp1.next = temp2.next;
temp2.next = temp1;
temp0.next = temp2;
}
}
}
return true;
}
|
五、单链表总结
单链表在结构上十分简单,但在实际操作中却十分的繁琐,像是删除添加等情况时总是需要找到要操作结点的前一个结点才能操作。但是单链表在增删等方面却要比数组的效率高,数组在指定位置增加删除时需要前后移动剩余的元素,效率相对较低。但数组在查询和修改方面的效率要比链表的效率高,因为数组不需要遍历即可对索引位置的数据进行操作。但单链表却要每次遍历找到相应的结点。
而且在HashMap集合的底层实现中是数组加链表的形式实现的,为了解决HashMap中的Hash冲突所以在数组中存放的便是链表。
双向循环链表
一、双向循环链表的基本信息
1、双向循环链表相比于单链表,在结点对象的属性里又多了一个pre引用,该引用的作用与next引用的作用刚好相反,pre是指向当前节点的前一个结点的引用;
2、双向循环链表相比于单链表还是在逻辑上成一个环状的结构,双向循环链表的尾结点的nextt域不是null,而是指向头结点,头结点的pre指向的是尾结点。之后只要在头结点和尾结点之间进行对节点的增删改查操作即可,如此可不用担心会破坏双向循环链表的逻辑环状结构。
双向循环链表的结构图
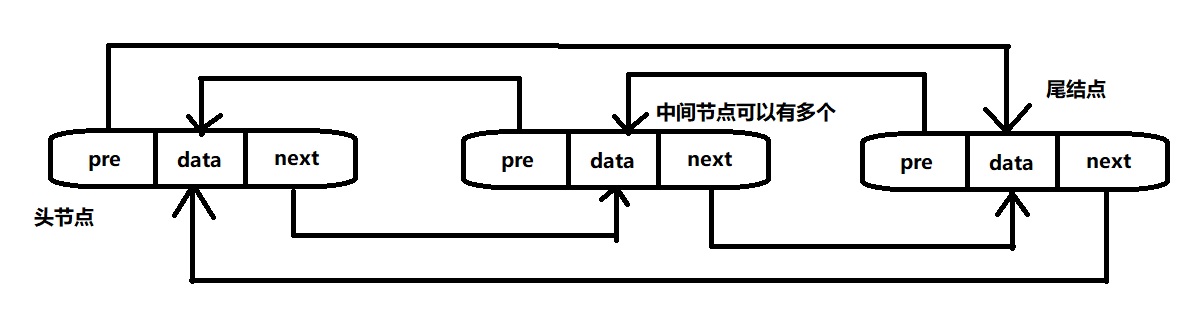
二、双向循环链表的结点
1、结点的私有属性
1
2
3
4
5
6
| public class DoubleLinkedNode {
int number;
Object object;
DoubleLinkedNode next;
DoubleLinkedNode pre;
}
|
2、结点的初始化
1
2
3
4
5
6
7
8
|
public DoubleLinkedNode() {
}
public DoubleLinkedNode(int number, Object object) {
this.number = number;
this.object = object;
}
|
三、双向循环链表的工具类
1、工具类的私有属性与构造器
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
| public class SingleLinkedNode {
private DoubleLinkedNode headNode;
private DoubleLinkedNode endNode;
private int size = 0;
public SingleLinkedNode(DoubleLinkedNode headNode) {
this.headNode = headNode;
endNode = new DoubleLinkedNode();
this.headNode.next = endNode;
endNode.pre = this.headNode;
this.headNode.pre = endNode;
endNode.next = this.headNode;
}
}
|
2、双向循环链表的非空判断
(1)思路
- 由于该链表是循环的链表,所以head.next永远不可能为null;
- 需要借助size工具类的私有属性来判断,当 size == 0 时链表为null。
(2)代码实现
1
2
3
4
5
6
7
8
9
10
11
12
|
public boolean isEmpty() {
if (size == 0) {
return true;
} else {
return false;
}
}
|
3、双向循环链表的遍历
(1)思路
- 由于循环链表的特性,所以使用for循环取遍历链表较为合适;
- 先判断链表非空;
- 创建一个临时引用指向第一个实际元素结点,循环遍历size次,输出结点信息。
(2)代码实现
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
public void traversal() {
if (isEmpty()) {
System.out.println("单链表为空!");
return;
}
DoubleLinkedNode temp = headNode.next;
for (int i = 0; i < size; i++) {
System.out.println(temp);
temp = temp.next;
}
}
|
4、根据位置索引查询结点信息
(1)思路
- 判断链表是否为空,为空则无需查找;
- 对index的数值进行校验;
- 当index == 0时返回头节点;
- 判断index的方位是在链表的前半部分还是后半部分,若是前半部分则从头结点开始遍历查找,反之则从尾结点开始查找。
(2)代码实现
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
|
public DoubleLinkedNode findByIndex(int index) {
if (index < 0 || index > size) {
System.out.println("您输入的位置索引有误!");
return null;
}
if (index == 0) {
return headNode;
}
if (index <= (size / 2)) {
DoubleLinkedNode temp1 = headNode.next;
for (int i = 1; i < index; i++) {
temp1 = temp1.next;
}
return temp1;
}else {
DoubleLinkedNode temp2 = endNode.pre;
for (int i = 1; i <= (size - index); i++) {
temp2 = temp2.pre;
}
return temp2;
}
}
|
5、向双向循环链表的尾部添加结点
(1)思路
- 根据传入的参数创建一个新的结点对象;
- 创建一个临时变量引用,调用findByIndex()方法,让临时变量引用指向最后一个结点;
- 找到最后一个节点,让最后一个结点的next指向新加入的结点,让尾结点的pre也指向新加入的结点;
- 让新结点的pre指向原最后一个结点,让新结点的next指向尾结点。
(2)代码实现
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
|
public void add(int number, Object object) {
DoubleLinkedNode addNode = new DoubleLinkedNode(number, object);
DoubleLinkedNode temp;
temp = findByIndex(size);
temp.next = addNode;
addNode.next = endNode;
addNode.pre = temp;
endNode.pre = addNode;
size++;
}
public void add(DoubleLinkedNode addNode) {
add(addNode.number, addNode.object);
}
|
6、向双向循环链表的指定位置添加结点
(1)思路
- 先对要插入的index进行数值检测;
- 根据传入的参数创建要插入的结点;
- 创建一个临时结点变量引用;
- 找到要index位置处的结点对象让临时变量的引用指向该节点;
- 让新加入的结点的next指向index位置处的结点对象,;
- 使新加入结点的pre指向index位置处的结点对象的前一个结点。
(2)代码实现
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
|
public void addByIndex(int index, int number, Object object) {
if (size < index || index <= 0) {
System.out.println("您插入的位置有误!");
return;
}
DoubleLinkedNode addNode = new DoubleLinkedNode(number, object);
DoubleLinkedNode temp = headNode.next;
for (int i = 1; i < index; i++) {
temp = temp.next;
}
addNode.pre = temp.pre;
temp.pre.next = addNode;
temp.pre = addNode;
addNode.next = temp;
size++;
}
public void addByIndex(int index,DoubleLinkedNode addNode){
addByIndex(index,addNode.number,addNode.object);
}
|
7、向双向循环链表的头部添加结点
(1)思路
- 根据传入的参数创建一个新加入节点对象;
- 将头结点的next赋值给新加入结点的next,将第一个结点的pre指向新加入的结点;
- 将新加入的结点赋值给头结点的next,修改新加入的结点的pre为头结点。
(2)代码实现
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
|
public void addFirst(int number,Object object){
DoubleLinkedNode addNode = new DoubleLinkedNode(number,object);
addNode.next = headNode.next;
headNode.next.pre = addNode;
headNode.next = addNode;
addNode.pre = headNode;
size++;
}
public void addFirst(DoubleLinkedNode addNode){
addFirst(addNode.number,addNode.object);
}
|
8、删除指定位置的结点对象
(1)思路
- 先判断链表是否为空,若为空则结束运行;
- 调用findByIndex()方法找到要删除的结点对象,此时是对index进行了校验的,所以无需校验;
- 将要删除结点后一个结点赋值给删除节点的前一个结点的next,修改要删除结点后一个结点的pre为要删除结点的前一个结点。
(2)代码实现
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
public DoubleLinkedNode removerByIndex(int index){
if (isEmpty()) {
System.out.println("双向链表为空!无法删除!");
return null;
}
DoubleLinkedNode delNode = findByIndex(index);
delNode.next.pre = delNode.pre;
delNode.pre.next = delNode.next;
size--;
return delNode;
}
|
9、删除双线链表的头结点
(1)思路
- 先判断链表非空,若为空则无法删除;
- 创建一个临时结点引用指向要删除的结点对象;
- 修改头结点与要删除节点的后一个结点的next与pre指向对象即可;
(2)代码实现
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
public DoubleLinkedNode removerFirst(){
if (isEmpty()) {
System.out.println("链表为空!无法删除");
return null;
}
DoubleLinkedNode delNode = headNode.next;
headNode.next.next.pre = headNode;
headNode.next = headNode.next.next;
size--;
return delNode;
}
|
10、根据索引修改指定位置的结点对象
(1)思路
- 使用findByIndex()方法找到要修改的那个结点对象,findByIndex()方法已经对index进行校验了所以无需再次校验;
- 对找到的结点进行判断,若为null则说明要删除的结点对象不存在;
- 若存在则修改找到的结点的number与object。
(2)代码实现
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
|
public DoubleLinkedNode updByIndex(int index,int number,Object object){
DoubleLinkedNode updNode = findByIndex(index);
if (updNode == null) {
return null;
}
DoubleLinkedNode temp = updNode;
updNode.number = number;
updNode.object = object;
return temp;
}
public DoubleLinkedNode updByIndex(int index,DoubleLinkedNode newNode){
return updByIndex(index,newNode.number,newNode.object);
}
|
11、对双向循环链表进行排序
(1)思路
- 先对链表判断是非空,若链表为空则无法排序;
- 本次选择使用快速选择排序的算法进行排序;
- 该算法的排序思路是每次遍历找到最小的那个节点的索引放在链表的前端和次前端。
(2)代码实现
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
|
public boolean sort(){
if (isEmpty()) {
System.out.println("链表为空,无法排序!");
return false;
}
int minIndex;
DoubleLinkedNode temp = null;
DoubleLinkedNode minNode = null;
DoubleLinkedNode temp1 = null;
for (int i = 1; i <= size; i++) {
temp1 = minNode = findByIndex(i);
minIndex = i;
for (int j = i + 1; j <= size; j++) {
temp = findByIndex(j);
if (minNode.number > temp.number) {
minIndex = j;
minNode = temp;
}
temp = temp.next;
}
int number = temp1.number;
Object object = temp1.object;
updByIndex(i,minNode);
updByIndex(minIndex,number,object);
}
return true;
}
|
四、双向循环链表的总结
双向循环链表的结构虽然比单链表要复杂一些,但在实际的操作中却要比单链表方便很多。因为双向链表不需要再像单链表一样始终要去寻找前一个结点,双向链表只需要找到相应要操作的结点即可完成对应的操作。
在LinkedList集合底层实现时,所使用的就是双向循环链表。
约瑟夫问题(josephu)
一、约瑟夫环基本介绍
1、简介
设编号为1,2,….n的n个人围成一个环坐在一起,约定编号为k的人(1 <= k <= n)的人从1开始报数,数到m的那个人出列,他的下一个位又从1开始报数,数到m的人再次出列,一次类推,直到所有人出列为止,由此产生一个出队的编号序列。
2、示意图
(1)初始状态
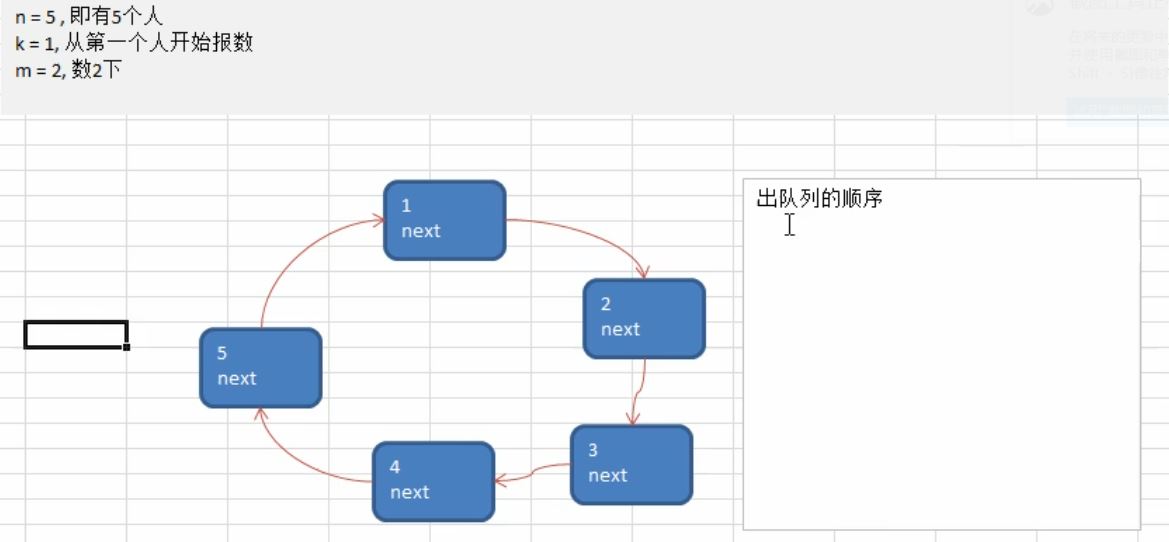
(2)出队列结束后的示意图

二、实现方式
1、实现技术方式
采用双向循环链表的方式实现约瑟夫问题
2、实现代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
|
public String josephu(int n,int k,int m) {
if (n <= 0 || k <= 0 || m <= 0) {
System.out.println("您输入的参数有误!");
return null;
}
for (int i = 0; i < size; i++) {
removerFirst();
}
for (int i = 1; i <= n; i++) {
add(i,null);
}
DoubleLinkedNode temp = headNode.next;
for (int i = 0; i < k -1; i++) {
temp = temp.next;
}
StringBuilder str = new StringBuilder();
while (size > 0){
for (int i = 0; i < m - 1; i++) {
temp = temp.next;
}
while (temp.number == 0){
temp = temp.next;
}
if (size != 1) {
str.append(temp.number + " -> ");
}else {
str.append(temp.number);
}
temp.pre.next = temp.next;
temp.next.pre = temp.pre;
temp = temp.next;
size--;
}
return str.toString();
}
|
3、测试代码
1
2
3
4
5
6
| public static void main(String[] args) {
DoubleLinkedNode headNode = new DoubleLinkedNode();
SingleLinkedNode node = new SingleLinkedNode(headNode);
String josephu = node.josephu(5, 1, 2);
System.out.println(josephu);
}
|



